Machines don't fight wars. Terrain doesn't fight wars. Humans fight wars. You must get into the mind of humans. That's where the battles are won.
- COL John R. Boyd
Intelligence Analysis: How to Think in Complex Environments fills a void in the existing literature on contemporary warfare by examining the theoretical and conceptual foundations of effective modern intelligence analysis—the type of analysis needed to support military operations in modern, complex operational environments. This volume is an expert guide for rethinking intelligence analysis and understanding the true nature of the operational environment, adversaries, and most importantly, the populace.
Intelligence Analysis proposes substantive improvements in the way the U.S. national security system interprets intelligence, drawing on the groundbreaking work of theorists ranging from Carl von Clauswitz and Sun Tzu to M. Mitchell Waldrop, General David Petraeus, Richards Heuer, Jr., Orson Scott Card, and others. The new ideas presented here will help the nation to amass a formidable, cumulative intelligence power, with distinct advantages over any and all adversaries of the future regardless of the level of war or type of operational environment.
Principles of Professional Ethics for the Intelligence Community
Intelligence Reform and Terrorism Prevention Act of 2004
Public Law 108-458
Further Strengthening the Sharing of Terrorism Information to Protect Americans (Exec. Order No. 13388)
Pub. Law 95-511
National Security Act
Department of Justice Releases Documents on Pen Registers and Trap and Trace Applications to the FISC
Joint Statement by Director of National Intelligence James Clapper and Attorney General Eric Holder on the Declassification of Additional Documents Regarding Collection Under Section 501 of the Foreign Intelligence Surveillance Act
FISC Approves Government’s Request to Modify Telephony Metadata Program
DNI Clapper Declassifies Additional Documents Regarding Collection Under Section 501 of the Foreign Intelligence Surveillance Act
Readout of the IC Leadership’s Meeting with the President’s Review Group on Intelligence and Communications Technologies
Foreign Intelligence Surveillance Court Approves Government’s Application to Renew Telephony Metadata Program
DNI Clapper Declassifies Additional Intelligence Community Documents Regarding Collection Under Section 501 of the Foreign Intelligence Surveillance Act
DNI Clapper Declassifies Additional Intelligence Community Documents Regarding Collection Under Section 501 of the Foreign Intelligence Surveillance Act
Foreign Intelligence Surveillance Court Approves Government’s Application to Renew Telephony Metadata Program
DNI Clapper Declassifies Intelligence Community Documents Regarding Collection Under Section 501 of the Foreign Intelligence Surveillance Act (FISA)
DNI Clapper Directs Annual Release of Information Related to Orders Issued Under National Security Authorities
Joint Statement: NSA and Office of the Director of National Intelligence
DNI Declassifies Intelligence Community Documents Regarding Collection Under Section 702 of the Foreign Intelligence Surveillance Act (FISA)
The job of protecting security and privacy - ODNI's Alex Joel discusses his role as the Intelligence Community's Civil Liberties Protection Officer
DNI Clapper Announces Review Group on Intelligence and Communications Technologies Monday
DNI Clapper Declassifies and Releases Telephone Metadata Collection Documents
Defunding FISA Business Records program risks dismantling important intelligence tool
Foreign Intelligence Surveillance Court Renews Authority to Collect Telephony Metadata
DNI Clapper Letter on Misunderstandings Arising from his March 12th Appearance Before the Senate Select Committee on Intelligence
ODNI Statement on the Limits of Surveillance Activities
Statement from the ODNI Spokesperson on the Latest Report from The Guardian
DNI Statement on the Collection of Intelligence Pursuant to Section 702 of the Foreign Intelligence Surveillance Act
Facts on the Collection of Intelligence Pursuant to Section 702 of the Foreign Intelligence Surveillance Act
DNI Statement on Activities Authorized Under Section 702 of FISA
DNI Statement on Recent Unauthorized Disclosures of Classified Information
American Bar Association, 23rd Annual Review of the Field of National Security Law, Executive Updates on Developments in National Security Law, Panel: Privacy, Technology and National Security: An Overview of Intelligence Collection
Privacy, Technology & National Security: An Overview of Intelligence Collection by Robert S. Litt, ODNI General Counsel
Transcript: Newseum Special Program - NSA Surveillance Leaks: Facts and Fiction
Director James R. Clapper Interview With Andrea Mitchell
Remarks as delivered by James R. Clapper Director of National Intelligence, Open Hearing on Continued Oversight of the Foreign Intelligence Surveillance Act to the House Permanent Select Committee on Intelligence
Remarks as delivered by James R. Clapper, Director of National Intelligence at an Open Hearing on Foreign Intelligence Surveillance Authorities
Hearing of the House Judiciary Committee, Opening Statement of Mr. Robert S. Litt, General Counsel, ODNI
Semi-Annual Assessment of Compliance with the Procedures and Guidelines Issued Pursuant to Section 702 of the Foreign Intelligence Surveillance Act, Submitted by the Attorney General and the Director of National Intelligence
DNI Letter to House and Senate Leaders with FISA Amendments Act 2012 Legislative Proposal
Joint Letter from DNI Clapper and Attorney General Eric Holder Urging Reauthorization of Title VII of the FAA
May 2010 Final Release of Semi-Annual FISA Compliance Assessment with Exemptions
December 2009 Final Release of Semi-Annual FISA Compliance Assessment with Exemptions
March 2009 Final Release of Semi-Annual FISA Compliance Assessment with Exemptions
Department of Justice Releases Documents on Pen Registers and Trap and Trace Applications to the FISC
Joint Statement by Director of National Intelligence James Clapper and Attorney General Eric Holder on the Declassification of Additional Documents Regarding Collection Under Section 501 of the Foreign Intelligence Surveillance Act
FISC Approves Government’s Request to Modify Telephony Metadata Program
DNI Clapper Declassifies Additional Documents Regarding Collection Under Section 501 of the Foreign Intelligence Surveillance Act
Readout of the IC Leadership’s Meeting with the President’s Review Group on Intelligence and Communications Technologies
Foreign Intelligence Surveillance Court Approves Government’s Application to Renew Telephony Metadata
National Counterterrorism Center Guidelines
Civil Liberties and Privacy Protections Incorporated Into Updated NCTC Guidelines
Overview of NCTC’s Data Access as Authorized by the 2012 Attorney General Guidelines
NCTC’s Annual Report on the Access, Retention, Use and Dissemination of United States Person Information For the Period March 23, 2012 through March 31, 2013
Memorandum of Agreement Between the Department of Homeland Security and the National Counterterrorism Center Regarding Advance Passenger Information System Data
Privacy Documents
Federal Register, Vol. 75, No. 181 (9/20/2010), pages 57163-57167
Privacy Act Regulations
Implementation of ISE Privacy Guidelines for Sharing Protected Information
Systems of Records Notices
Federal Register, Vol. 72, No. 248 (12/28/2007), pages 73887-73898
Federal Register, Vol. 72, No. 248 (12/28/2007), pages 73899-73904
Federal Register, Vol. 75, No. 63 (4/2/2010), pages 16853-16868
Federal Register, Vol. 76, No. 138 (7/19/2011), pages 42737-42750
Central Intelligence Agency Act of 1949 (Public Law 110 of June 20
National Security Agency Act of 1959
National Imagery and Mapping Agency Act of 1996
Intelligence Reform and Terrorism Prevention Act of 2004 (for ODNI)
Intelligence Reform and Terrorism Prevention Act of 2004 (for FBI)
Intelligence Reform and Terrorism Prevention Act of 2004 (for DHS)
Implementing Recommendations of the 9/11 Commission Act of 2007
Civil Liberties and Privacy Information Paper: Description of Civil Liberties and Privacy Protections Incorporated in the 2008 Revision of Executive Order 12333, Office of the Director of National Intelligence/Civil Liberties and Privacy Office, August 2008
Implementing Recommendations of the 9/11 Commission Act of 2007
Homeland Security Act of 2002
Homeland Security Act of 2002 Overview
Precision agriculture (PA)–defined as a set of technologies that combines acquisition, analysis, management, and delivery of information to help make site-specific decisions, with the ultimate goal of optimizing production–will play an important role in addressing this grand challenge. At the heart of the evolving tools, technologies, and information management strategies found in precision agriculture is remote sensing. However, the technology of capturing, analyzing, storing, and delivering the remotely sensed observations associated with precision agriculture is changing rapidly, thus making it difficult to keep up with the ever-expanding volume of scientific research. It is time to take stock of the current state-of-the-art in the remote sensing associated with precision agriculture.
A total of 25 papers are published, e.g.,
Tilly, N.; et al. Fusion of Plant Height and Vegetation Indices for the Estimation of Barley Biomass. Remote Sens. 2015, 7, 11449–11480. Mesas-Carrascosa, F.-J.; et al. Assessing Optimal Flight Parameters for Generating Accurate Multispectral Orthomosaicks by UAV to Support Site-Specific Crop Management. Remote Sens. 2015, 7, 12793-12814. Gonzalez-Dugo, V.; et al. Using High-Resolution Hyperspectral and Thermal Airborne Imagery to Assess Physiological Condition in the Context of Wheat Phenotyping. Remote Sens. 2015, 7, 13586-13605.
Growers today can take advantage of the latest in technology to help them maintain an edge in an increasingly competitive marketplace. That means securing the benefits of the information revolution to deliver advances in crop yield and farm efficiency from precision growing techniques enabled by data – lots of data.
Those benefits, of course, are only going to be as good as the underlying data provided by sensors, the devices that obtain information about an area — a field — often from a distance in what’s called remote sensing.
Joseph Byrum
This information is collected, compiled and turned into actionable intelligence through the use of advanced data analytics. Think of the navigation app on a smartphone. At heart, it is a data analytics tool that runs through all of the possible routes to between your current location and your destination, estimating how long it will take to take one road compared to the next. Yet these apps are only as good as the traffic data that let the system know one road is closed and another is clogged with traffic. The job of sensors is to provide that data.
Origins of Remote Sensing
Remote sensing may be a relatively new thing to agriculture, but the concept has been around for quite some time. Back in the mid-19th century, man took to the skies in hot air balloons with bulky, primitive cameras they used to survey the land below and create highly accurate maps. World War I commanders soon came to rely on photographs taken from biplanes and blimps to stay informed about the enemy’s battlefield movements and to plan artillery strikes. These commanders understood that, if you can’t see it, you can’t manage it.
Over the ensuing decades, technology advanced rapidly, but this principle remained the same. Cameras became far less cumbersome, and aircraft became far more capable. The “bird’s eye view” provided by these systems became exponentially more effective in managing tasks as diverse as construction, mining, and archeology. In the 1960s, surveying was boosted into orbit as satellites gave us, for the first time, a look at the entire planet at a single glance, which provided insight into managing big picture issues from global temperatures to land use patterns.
The Potential for Remote Sensing in Agriculture
Modern sensing instruments have advanced far beyond simple photographic film. Today’s devices measure light, radiation, and heat by capturing different wavelengths of the electromagnetic spectrum. Ongoing electronics miniaturization and the popularity of commercial drones have made this equipment increasingly affordable, but the usefulness of these devices in agriculture took the greatest leap with the advent of GIS (geographical information systems), the technology that allows the organization and analysis of data and patterns related to specific locations on a map — such as a field. This made it far easier for combined systems to deliver information — actionable intelligence — related to a grower’s specific needs.
Remote sensing devices take measurements throughout a field over time so that the grower can analyze conditions based on the data and take action that will have a positive influence on the harvest outcome. For instance, sensors can serve as an early warning system allowing a grower to intervene, early on, to counter disease before it has had a chance to spread widely. They can also perform a simple plant count, evaluate plant health, estimate yield, assess crop loss, manage irrigation, detect weeds, identify crop stress and map a field.
A variety of sensors is available to perform one or more of these tasks. Which one will a grower need? It all depends. A small-scale vegetable farmer will have different needs than a commercial grain farmer managing multiple fields.
Sensor Platforms
Sensors can be grouped according to their enabling technology — ground sensors, aerial sensors and satellite sensors. Ground sensors are handheld, mounted on tractors and combines, or free-standing in a field. Common uses for these include evaluating nutrient levels for more specific chemical and nutrient application, measuring weather, or the moisture content of the soil.
Aerial sensors have become far more affordable with the advent of drone technology that places the bird’s-eye view of a field within reach of most farmers. They are also attached to airplanes, another relatively cheap option. The systems are capable of capturing high-resolution images and data slowly enough, at low altitude, to enable thorough analysis. Typical uses include plant population count, weed detection, yield estimates, measuring chlorophyll content and evaluating soil salinity. The downside of aerial platforms is that wind and cloud cover can limit their use.
Satellite sensors provide coverage of vast land areas and are especially useful for monitoring crops status, calculating losses from severe weather events and conducting yield assessments. Initially, such systems were tailored to the needs of the military and government, not agriculture. So the main downside, aside from cost, was that these systems were tasked in advance — usually months — to look at a specific area at a certain time. Worst of all, cloud cover could ruin that expensive purchase. Now many governments have opened up satellite imaging databases to the public, providing an important and accessible resource for understanding crop conditions.
The Sensors Themselves
As with the choice of platform, appropriate sensor types will vary from farm-to-farm. A grower must ask what he intends to measure, and why, and which sensor type is best suited to the crop management and planning task at hand. In the past, there wasn’t a choice. The only sensor was camera film that captured a narrow slice of the electromagnetic spectrum — visible light. Now sensors go far beyond that, measuring short-wavelength gamma radiation at one end and low-frequency radio waves at the other.
Farmers find the most useful information closer to the visible spectrum, as color can be used to measure a plant’s chlorophyll levels and provide insight into a plant’s health and growth status. Simple red-green-blue sensors can provide color information, but more sophisticated data are available by peering into the near-infrared and short-wave infrared spectral bands.
The way leaves reflect light in the infrared spectrum changes if a plant’s cell structure is damaged, or if its water content is abnormal. The most consistent mathematical model to express this is called the normalized difference vegetation index, or NDVI. With near-infrared and red-edge (NIR and RE) sensors, NDVI can identify stressed crops much more precisely, giving the farmer more time to take corrective action.
The same sensors can also be used to identify a soil salinity problem over time, which can be a sign of poor irrigation that threatens crop yields. Salty soil has a higher reflectance than normal soil, a difference that shows up in the infrared spectrum and on thermal cameras.
Thermal cameras peer into long-wavelength infrared bands and measure heat, often represented as colors. So a farmer, shortly after irrigating his field, can send a drone equipped with a LWIR sensor and readily see, from the colors on the map, areas in the field that aren’t receiving enough water. This helps get the irrigation right from the beginning, preventing yield loss.
Radar and microwave sensors on satellites cut through weather conditions and provide powerful agricultural monitoring data across entire continents. Some sensors are designed to capture broad swaths of the electromagnetic spectrum, while others are tailored to measuring narrow slices that are relevant to a specific type of analysis. Which one is right for the grower is going to depend on what the grower intends to accomplish.
Outside the electromagnetic spectrum, there are the ubiquitous GPS sensors that offer precise positional data that make things like self-driving tractors possible. Various types of weather stations allow the logging of environmental conditions, such as rain, temperature, sunlight and other factors that provide insight into crop performance.
What’s the Right Sensing Option?
The more sophisticated the sensor, the higher the cost. Farmers must always weigh the potential for increased yield against the capital investment cost of each sensing platform.
In many ways, the problem is that a farmer interested in remote sensing has too many options. The most effective use of remote sensing would be to have a collection of sensors measuring multiple aspects of the plant growing process, but so far technology suppliers are not making this easy. They tend to offer proprietary solutions that don’t play well with sensors from other vendors. That leaves farmers in a Wild West situation, with no data standards and limited interoperability. Data sharing is inconvenient, if not impossible.
As is always the case, the market can sense these needs, and some startup companies have formed to offer integrated hardware and software solutions. It will just take time for these packages to mature and become viable, high-value propositions for most growers. Likewise, organizations like the Open Data Institute are working to promote open standards that will promote agricultural innovation.
Sensing technologies are evolving rapidly, which means it’s often up to farmers to use trial and error to determine what off-the-shelf products can deliver a “quick fix,” and which can be scientifically validated to contribute to increasing yield and profits over time.
==========
Editor’s Note:Joseph Byrum is senior R&D and strategic marketing executive in Life Sciences – Global Product Development, Innovation, and Delivery at Syngenta. He is a regular contributor to AgFunderNews.
American firms have begun to operate their own imaging satellite systems, aiming to become an important part of the U.S. commercial remote sensing industry. To succeed over the long run, these new U.S. commercial remote sensing satellite firms need a combination of reliable technologies, government policies that encourage U.S. industry competitiveness, a strong international presence, and sound business plans to ensure their competitiveness in both the domestic and international marketplaces. The greatest risks for the these firms come from the challenge of transforming themselves from imagery data providers to strong competitors as information age companies; the need to master the technical risks of building and operating sophisticated imaging satellite systems; and the requirement to operate effectively in a complex international business environment. In addition, the government's policymaking process has yet to achieve the degree of predictability, timeliness, and transparency that the firms need if they are expected to operate effectively in a highly competitive and rapidly changing global marketplace. The authors conclude with six recommendations that the U.S. Department of Commerce should adopt to best fulfill its responsibilities for promoting the U.S. commercial remote sensing industry and for encouraging the competitiveness of new private imaging satellite firms. Source: https://www.rand.org/pubs/monograph_reports/MR1469.html
•High precision positioning systems (like GPS)are the key technology to achieve accuracy when driving in the field, providing navigation and positioning capability anywhere on earth, anytime under any all conditions. The systems record the position of the field using geographic coordinates (latitude and longitude) and locate and navigate agricultural vehicles within a field with 2cm accuracy.
•Automated steering systems: enable to take over specific driving tasks like auto-steering, overhead turning, following field edges and overlapping of rows. These technologies reduce human error and are the key to effective site management:
Assisted steering systemsshow drivers the way to follow in the field with the help of satellite navigation systems such as GPS. This allows more accurate driving but the farmer still needs to steer the wheel.
Automated steering systems, take full control of the steering wheel allowing the driver to take the hands off the wheel during trips down the row and the ability to keep an eye on the planter, sprayer or other equipment.
Intelligent guidance systems provide different steering patterns (guidance patterns) depending on the shape of the field and can be used in combination with above systems.
Caption: Seeder using a geomapping system
• Geomapping: used to produce maps including soil type, nutrients levels etc in layers and assign that information to the particular field location. (see picture on the left)
• Sensors and remote sensing: collect data from a distance to evaluating soil and crop health (moisture, nutrients, compaction, crop diseases). Data sensors can be mounted on moving machines.
• Integrated electronic communications between components in a system for example, between tractor and farm office, tractor and dealer or spray can and sprayer.
•Variable rate technology (VRT): ability to adapt parameters on a machine to apply, for instance, seed or fertiliser according to the exact variations in plant growth, or soil nutrients and type.
Precision Agriculture: An International Journal on Advances in Precision Agriculture
Deep Learning Patterns, Methodology and Strategy @ IntuitionMachine.com
What I want to talk to you about today is the Holographic Principle and how it provides an explanation to Deep Learning. The Holographic Principle is a theory (see: Thin Sheet of Reality) that explains how quantum theory and gravity interact to construct the reality that we are in. The motivations for this theory comes from the paradox that Hawking created when he theorized that black holes would emanate energy. The fundamental concept that had been violated by Hawking’s theory was that information was destroyed. As a consequence of this paradox, through several decades of research and experimentation, physicists have brought forth a unified theory of the universe that is based on information theoretic principles. The entire universe is a projection of a hologram. It is entirely fascinating that the arrow of time and the existence gravity are but mere manifestations of informationentanglement!
Now, you may be mistaken to think that this Holographic Principle is just some fringe idea from physics. It appears at first read to be quire a wild idea! Apparently though, the theory rests on very solid experimental and theoretical underpinnings. Let’s just say that Stephen Hawking who first remarked that is was ‘rubbish’ has finally agreed to its conclusions. So at this time, it should be relatively safe to start deriving some additional theories of this principle.
One surprising consequence of this theory is that the hologram is able to capture the dynamics of the universe that has of the order of d^N degrees of freedom (where d is the dimension and N is the number of particles). One would think that the hologram would be of equal size, but it is not. It is a surface area and is proportional only to N². This begs the question, how is an structure of order N² able to capture the dynamics of a system in d^N?
In the meantime, Deep Learning (DL) coincidentally has a similar mapping problem. Researchers don’t know how it is possible for DL to perform so impressively well considering the problem domain’s search space has an exceedingly high dimension. So, Max Tegmark and Henry Lin of Harvard, have volunteered their own explanation “Why does deep and cheap learning work so well?” In their paper they argue the following:
… although well-known mathematical theorems guarantee that neural networks can approximate arbitrary functions well, the class of functions of practical interest can be approximated through “cheap learning” with exponentially fewer parameters than generic ones, because they have simplifying properties tracing back to the laws of physics. The exceptional simplicity of physics-based functions hinges on properties such as symmetry, locality, compositionality and polynomial log-probability, and we explore how these properties translate into exceptionally simple neural networks approximating both natural phenomena such as images and abstract representations thereof such as drawings.
The authors bring up several promising ideas like the “no-flattening theorems” as well as the use of information theory and the renormalization group as explanations for their conjecture. I however was not sufficiently convinced by their argument. The argument assumes that all problem data follows ‘natural laws’, but as we all know that DL can be effective in unnatural domains. See, Identifying cars, driving, creating music and playing Go as trivial examples of clearly an unnatural domain. To be fair, I think that they were definitely on to something, and that something I discuss in more detail .
In this article, I make a bold proposal with an argument that is somewhat analogous to what Tegmark and Lin proposed. Deep Learning works so well because of physics. However, the genesis of my idea is that DL works because it uses the leverages the same computational mechanisms underlying the Holographic Principle. Specifically, the capability of representing an extremely high dimensional space (i.e. d^N) with a paltry number of parameters of the order N².
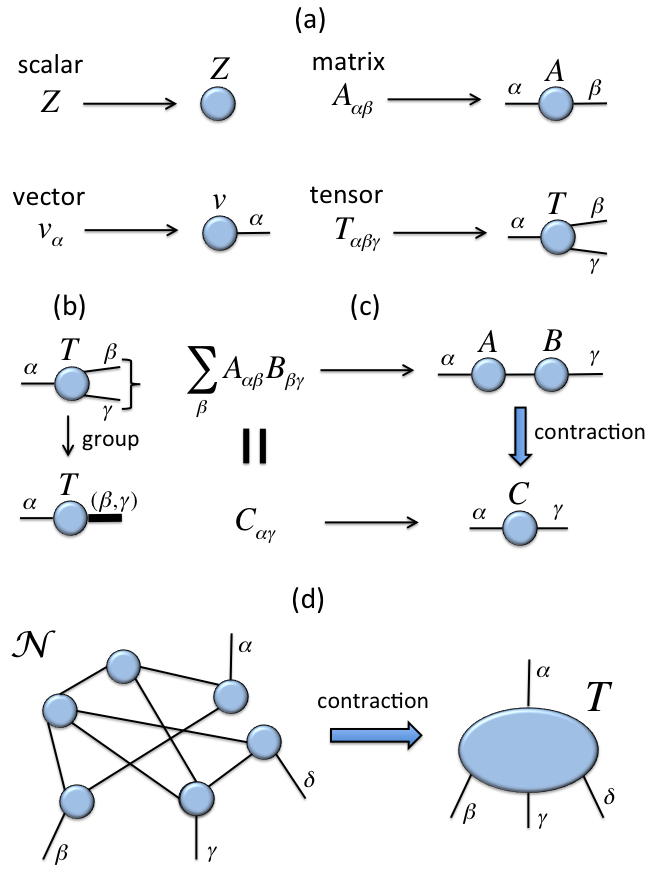
The computational mechanism underpinning the Holographic Principle can be most easily depicted through the use of Tensor Networks (note: These are somewhat different from the TensorFlow or the Neural Tensor Network). Tensor network notation is as follows:
The value of tensor networks in physics is that they are used to drastically reduce the state space into a network that focuses only on the relevant physics. The primary motivation behind the use of Tensor Networks is to reduce computation. A tensor network is a way to perform computation in a high dimensional space by decomposing a large tensor into smaller more manageable parts. The computation can then be performed with smaller parts at a time. By optimizing each part one effectively optimizes the full larger tensor.
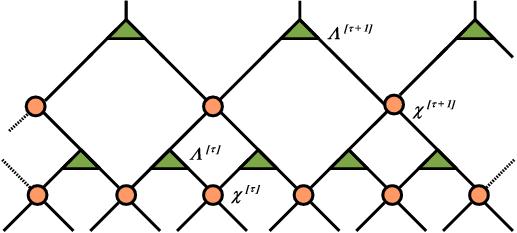
In the context of the holographic principle, the MERA tensor is used and it is depicted as follows:
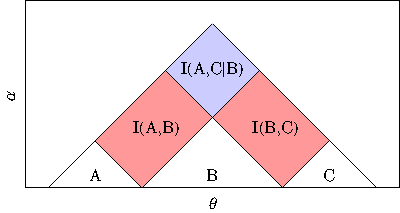
In above the circles depict “disentanglers” and the triangles “isometries”. One can look at the nodes from the perspective of a mapping. That is the circles map matrices to other matrices. The triangles take a matrix and map it to a vector. The key though here is to realize that the ‘compression’ capability arises from the hierarchy and the entanglement. As a matter of fact, this network embodies the mutual information chain rule:
In other words, as you move from the bottom to the top of the network, the information entanglement increases.
I’ve written earlier about the similarities of Deep Learning with ‘Holographic Memories’ however here I’m going to make one step further. Deep Learning networks are also tensor networks. Deep Learning networks however are not as uniform as a MERA network, however they exhibit similar entanglements. As information flows from input to output in either a fully connected network or a convolution network, the information are similarly entangled.
The use of tensor networks has been studied recently by several researchers. Miles Stoudenmire wrote a blog post: “Tensor Networks: Putting Quantum Wavefunctions into Machine Learning” where he describes his method applied to MNIST and CIFAR-10. He writes about one key idea about this approach:
The key is dimensionality. Problems which are difficult to solve in low dimensional spaces become easier when “lifted” into a higher dimensional space. Think how much easier your day would be if you could move freely in the extra dimension we call time. Data points hopelessly intertwined in their native, low-dimensional form can become linearly separable when given the extra breathing room of more dimensions.
Amnon Shashua et al. have also done work in this space. Their latest paper (Oct 2016) “Tensorial Mixture Models” proposes a novel kind of convolution network.
In conclusion, the Holographic Principle, although driven by quantum computation, reveals to us the existence of a universal computational mechanism that is capable of representing high dimensional problems using a relatively low number of model parameters. My conjecture here is that this is the same mechanism that permits Deep Learning to perform surprisingly well.
Most explanations about Deep Learning revolve around the 3 Ilities that I described here. These are expressibility, trainability and generalization. There is definitely consensus in “expressibility”, that is of a hierarchical network requiring less parameters that a shallow network. The open questions however are that of trainability and generalization. The big difficulty in explaining away these two is that they don’t fit with any conventional machine learning notion. Trainability should be impossible in a high-dimensional non-convex space, however simple SGD seems to work exceedingly well. Generalization does not make any sense without a continuous manifold, yet GANs show quite impressive generalizations:
The above figure shows the StackGAN generating, given text descriptions , output images in two stages. For the StackGAN there are two generative networks and it is difficult to comprehend how the second generator captures only image refinements. There are plenty of unexplained phenomena like this. The Holographic Principle provides a base camp to a plausible explanation.
The current mainstream intuition of why Deep Learning works so well is that there exists a very thin manifold in high-dimensional space that can represent the natural phenomena that it is trained on. Learning proceeds through the discover of this ‘thin manifold’. This intuition however breaks apart considering the recent experimental data (see: “Rethinking Generalization”). The authors of the ‘Rethinking Generalization) paper write:
Even optimization on random labels remains easy. In fact, training time increases only by a small constant factor compared with training on the true labels.
Both the Tegmark argument and the ‘Thin Manifold’ argument cannot possibly work with random data. This thus lead to the hypothesis that there should exist an entirely different mechanism that is reducing the degrees of freedom (or problem dimension) so that computation is feasible. This compression mechanism exists can be found in the structure of the DL network, just like it exists in the MERA tensor network.
Conventional Machine Learning thinking is that it is the intrinsic manifold structure of the data that needs to be discovered via optimization. In contrast, my conjecture claims that the data is less important, rather it is the topology of the DL network that is able to capture the essence of the data. That is, even if the bottom layers have random initializations, it is likely that the network should work well enough subject to a learned mapping at the top layer.
In fact, I would even make a bigger leap in that in our quest for unsupervised learning, we may have already overlooked the fact that a neural network has already created its own representation of the data at onset of random initialization. It is just our inability to interpret that representation that is problematic. A random representation that preserves invariances (i.e. locality, symmetry etc.) may just be a good as any other representation. Yann LeCun’s cake might already be present and that it is just the icing and cherry that needs to explain what the cake represents.
Note to reader: In 1991, psychologist Karl Pribham with physicist David Bohm had speculated about Holonomic Brain Theory. I don’t know the concrete relationship between the brain and deep learning. So I can’t make the same conclusion that they made in 1991.