The Holographic Principle: Why Deep Learning Works
What I want to talk to you about today is the Holographic Principle and how it provides an explanation to Deep Learning. The Holographic Principle is a theory (see: Thin Sheet of Reality) that explains how quantum theory and gravity interact to construct the reality that we are in. The motivations for this theory comes from the paradox that Hawking created when he theorized that black holes would emanate energy. The fundamental concept that had been violated by Hawking’s theory was that information was destroyed. As a consequence of this paradox, through several decades of research and experimentation, physicists have brought forth a unified theory of the universe that is based on information theoretic principles. The entire universe is a projection of a hologram. It is entirely fascinating that the arrow of time and the existence gravity are but mere manifestations of information entanglement!
Now, you may be mistaken to think that this Holographic Principle is just some fringe idea from physics. It appears at first read to be quire a wild idea! Apparently though, the theory rests on very solid experimental and theoretical underpinnings. Let’s just say that Stephen Hawking who first remarked that is was ‘rubbish’ has finally agreed to its conclusions. So at this time, it should be relatively safe to start deriving some additional theories of this principle.
One surprising consequence of this theory is that the hologram is able to capture the dynamics of the universe that has of the order of d^N degrees of freedom (where d is the dimension and N is the number of particles). One would think that the hologram would be of equal size, but it is not. It is a surface area and is proportional only to N². This begs the question, how is an structure of order N² able to capture the dynamics of a system in d^N?
In the meantime, Deep Learning (DL) coincidentally has a similar mapping problem. Researchers don’t know how it is possible for DL to perform so impressively well considering the problem domain’s search space has an exceedingly high dimension. So, Max Tegmark and Henry Lin of Harvard, have volunteered their own explanation “Why does deep and cheap learning work so well?” In their paper they argue the following:
… although well-known mathematical theorems guarantee that neural networks can approximate arbitrary functions well, the class of functions of practical interest can be approximated through “cheap learning” with exponentially fewer parameters than generic ones, because they have simplifying properties tracing back to the laws of physics. The exceptional simplicity of physics-based functions hinges on properties such as symmetry, locality, compositionality and polynomial log-probability, and we explore how these properties translate into exceptionally simple neural networks approximating both natural phenomena such as images and abstract representations thereof such as drawings.
The authors bring up several promising ideas like the “no-flattening theorems” as well as the use of information theory and the renormalization group as explanations for their conjecture. I however was not sufficiently convinced by their argument. The argument assumes that all problem data follows ‘natural laws’, but as we all know that DL can be effective in unnatural domains. See, Identifying cars, driving, creating music and playing Go as trivial examples of clearly an unnatural domain. To be fair, I think that they were definitely on to something, and that something I discuss in more detail .
In this article, I make a bold proposal with an argument that is somewhat analogous to what Tegmark and Lin proposed. Deep Learning works so well because of physics. However, the genesis of my idea is that DL works because it uses the leverages the same computational mechanisms underlying the Holographic Principle. Specifically, the capability of representing an extremely high dimensional space (i.e. d^N) with a paltry number of parameters of the order N².
The computational mechanism underpinning the Holographic Principle can be most easily depicted through the use of Tensor Networks (note: These are somewhat different from the TensorFlow or the Neural Tensor Network). Tensor network notation is as follows:
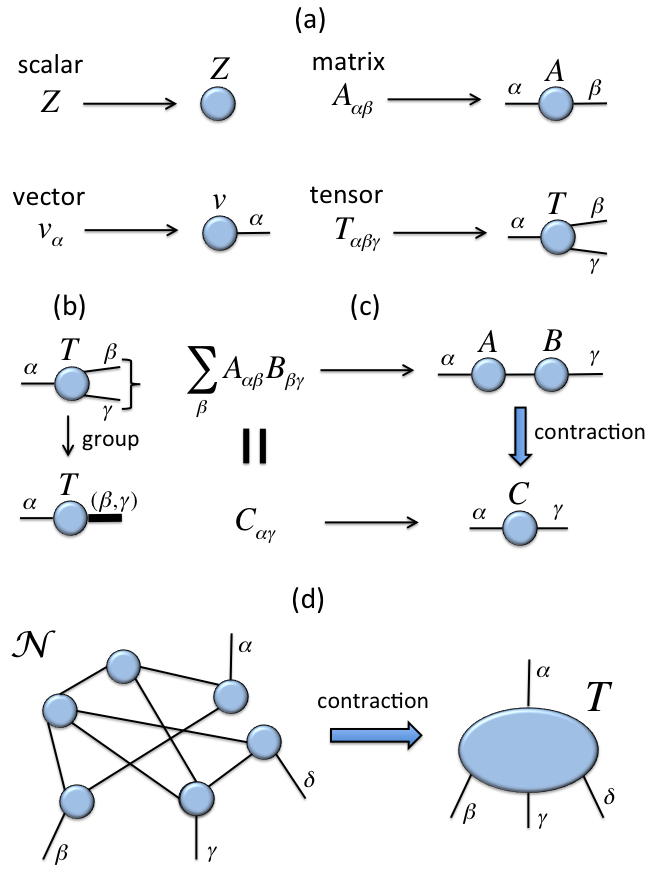
The value of tensor networks in physics is that they are used to drastically reduce the state space into a network that focuses only on the relevant physics. The primary motivation behind the use of Tensor Networks is to reduce computation. A tensor network is a way to perform computation in a high dimensional space by decomposing a large tensor into smaller more manageable parts. The computation can then be performed with smaller parts at a time. By optimizing each part one effectively optimizes the full larger tensor.
In the context of the holographic principle, the MERA tensor is used and it is depicted as follows:
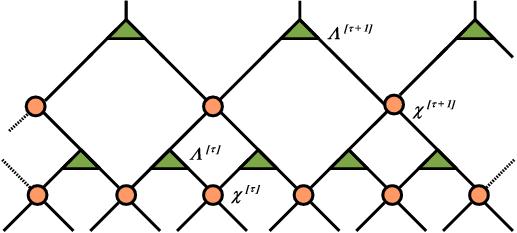
In above the circles depict “disentanglers” and the triangles “isometries”. One can look at the nodes from the perspective of a mapping. That is the circles map matrices to other matrices. The triangles take a matrix and map it to a vector. The key though here is to realize that the ‘compression’ capability arises from the hierarchy and the entanglement. As a matter of fact, this network embodies the mutual information chain rule:
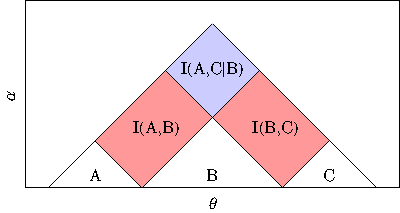
In other words, as you move from the bottom to the top of the network, the information entanglement increases.
I’ve written earlier about the similarities of Deep Learning with ‘Holographic Memories’ however here I’m going to make one step further. Deep Learning networks are also tensor networks. Deep Learning networks however are not as uniform as a MERA network, however they exhibit similar entanglements. As information flows from input to output in either a fully connected network or a convolution network, the information are similarly entangled.
The use of tensor networks has been studied recently by several researchers. Miles Stoudenmire wrote a blog post: “Tensor Networks: Putting Quantum Wavefunctions into Machine Learning” where he describes his method applied to MNIST and CIFAR-10. He writes about one key idea about this approach:
The key is dimensionality. Problems which are difficult to solve in low dimensional spaces become easier when “lifted” into a higher dimensional space. Think how much easier your day would be if you could move freely in the extra dimension we call time. Data points hopelessly intertwined in their native, low-dimensional form can become linearly separable when given the extra breathing room of more dimensions.
Amnon Shashua et al. have also done work in this space. Their latest paper (Oct 2016) “Tensorial Mixture Models” proposes a novel kind of convolution network.
In conclusion, the Holographic Principle, although driven by quantum computation, reveals to us the existence of a universal computational mechanism that is capable of representing high dimensional problems using a relatively low number of model parameters. My conjecture here is that this is the same mechanism that permits Deep Learning to perform surprisingly well.
Most explanations about Deep Learning revolve around the 3 Ilities that I described here. These are expressibility, trainability and generalization. There is definitely consensus in “expressibility”, that is of a hierarchical network requiring less parameters that a shallow network. The open questions however are that of trainability and generalization. The big difficulty in explaining away these two is that they don’t fit with any conventional machine learning notion. Trainability should be impossible in a high-dimensional non-convex space, however simple SGD seems to work exceedingly well. Generalization does not make any sense without a continuous manifold, yet GANs show quite impressive generalizations:

The above figure shows the StackGAN generating, given text descriptions , output images in two stages. For the StackGAN there are two generative networks and it is difficult to comprehend how the second generator captures only image refinements. There are plenty of unexplained phenomena like this. The Holographic Principle provides a base camp to a plausible explanation.
The current mainstream intuition of why Deep Learning works so well is that there exists a very thin manifold in high-dimensional space that can represent the natural phenomena that it is trained on. Learning proceeds through the discover of this ‘thin manifold’. This intuition however breaks apart considering the recent experimental data (see: “Rethinking Generalization”). The authors of the ‘Rethinking Generalization) paper write:
Even optimization on random labels remains easy. In fact, training time increases only by a small constant factor compared with training on the true labels.
Both the Tegmark argument and the ‘Thin Manifold’ argument cannot possibly work with random data. This thus lead to the hypothesis that there should exist an entirely different mechanism that is reducing the degrees of freedom (or problem dimension) so that computation is feasible. This compression mechanism exists can be found in the structure of the DL network, just like it exists in the MERA tensor network.
Conventional Machine Learning thinking is that it is the intrinsic manifold structure of the data that needs to be discovered via optimization. In contrast, my conjecture claims that the data is less important, rather it is the topology of the DL network that is able to capture the essence of the data. That is, even if the bottom layers have random initializations, it is likely that the network should work well enough subject to a learned mapping at the top layer.
In fact, I would even make a bigger leap in that in our quest for unsupervised learning, we may have already overlooked the fact that a neural network has already created its own representation of the data at onset of random initialization. It is just our inability to interpret that representation that is problematic. A random representation that preserves invariances (i.e. locality, symmetry etc.) may just be a good as any other representation. Yann LeCun’s cake might already be present and that it is just the icing and cherry that needs to explain what the cake represents.
Note to reader: In 1991, psychologist Karl Pribham with physicist David Bohm had speculated about Holonomic Brain Theory. I don’t know the concrete relationship between the brain and deep learning. So I can’t make the same conclusion that they made in 1991.
References
https://arxiv.org/pdf/1407.6552v2.pdf Advances on Tensor Network Theory: Symmetries, Fermions, Entanglement, and Holography
